Building Practical AI Agents
4 min read
“AI agents” is overloaded. A lot of demos are a prompt plus a loop plus vibes. I care about agents that close a real loop:
- produce an artifact (a summary, a report, a PR),
- verify it against explicit criteria,
- and revise until it’s acceptable (or fail loudly with a reason).
If you can’t explain the loop, instrument it, and test it with real inputs, you don’t have an agent. You have a generator.
TL;DR
- Make the loop explicit:
draft -> verify -> revisewith a max revision budget. - Verify against something concrete: schemas, checklists, citations, invariants, or policy gates.
- Log state transitions and the reasons for revisions. “It got better” is not a debug strategy.
- Treat tools as untrusted I/O: timeouts, retries, and bounded outputs.
- Keep the agent state visible to operators. If work, blockers, and memory are opaque, the system will feel smarter than it is.
The loop matters more than the model
The model choice matters. The loop matters more.
When an agent is reliable, it is usually because the control structure is boring:
- the input shape is constrained,
- the output artifact is inspectable,
- verification is explicit,
- retries are bounded,
- and failure is visible.
That pattern works whether the artifact is a summary, a docs patch, a deployment plan, or a DAG run in an operator UI.
Here is the smallest useful version:
class SpecState(TypedDict):
task: str
draft: str
verified: str
needs_revision: bool
revision_count: int
max_revisions: int
def _build_graph(self):
workflow = StateGraph(SpecState)
workflow.add_node("draft_step", self.draft_node)
workflow.add_node("verify_step", self.verify_node)
workflow.add_node("revise_step", self.revise_node)
workflow.set_entry_point("draft_step")
workflow.add_edge("draft_step", "verify_step")
workflow.add_conditional_edges(
"verify_step",
self.should_revise,
{"revise": "revise_step", "end": END}
)
workflow.add_edge("revise_step", "verify_step")
return workflow.compile()The point is not LangGraph specifically. The point is that the behavior is a state machine instead of an improvised conversation.
Current examples from my stack
This pattern now shows up in a few different places across the projects on this site:
1) News Analyzer: the pipeline is the product
The News Analyzer demo is the most literal example. It is an agentic content pipeline:
- collect inputs,
- extract content,
- draft a summary,
- enrich or verify,
- and deliver an artifact.
That is useful because the artifact is concrete and the pipeline stages are visible. You can inspect where it failed instead of treating the whole system like magic.
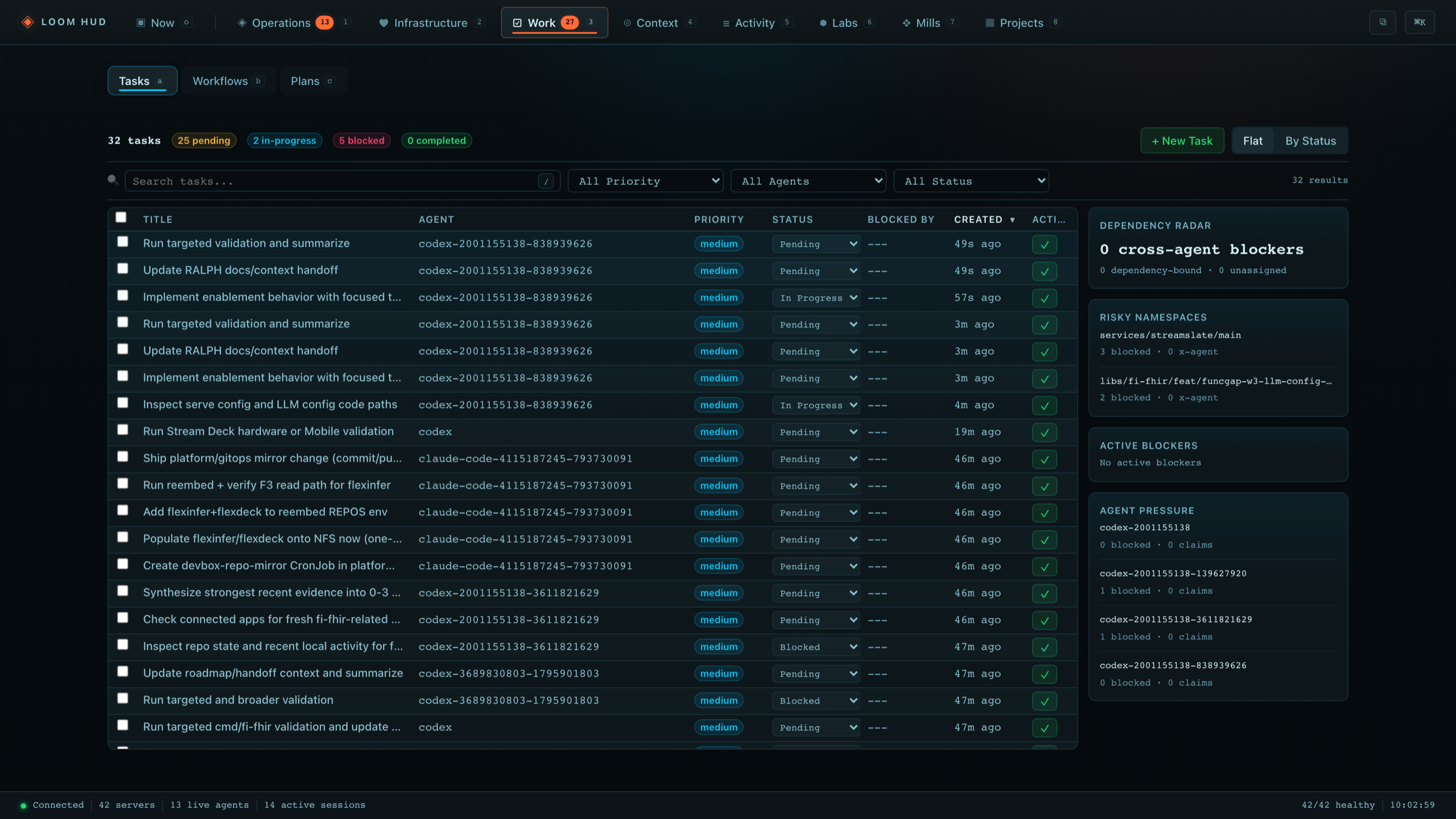
2) Loom Core: agent work becomes observable
In Loom Core, the interesting part is not “the agent can do things.” The interesting part is that sessions, tasks, memory, workflows, and server health are all visible in the HUD.
That matters operationally. Once agents touch repos, infra, or long-running workflows, you need to know:
- what the agent believes it is doing,
- what is blocked,
- what tool is slow,
- and what decision was recorded.
Without that, the agent may still be productive, but it won’t be trustworthy.
3) MentatLab: orchestration is an operator surface
MentatLab takes the same core idea and puts it in an operator-facing DAG workflow surface. That is a very different UX from a chat window, but the reliability pattern is the same:
- explicit steps,
- clear handoffs,
- visible state,
- approvals where needed,
- and an artifact at the end.
If a system affects real workflows, I want to be able to point at the graph and say where the risk lives.
Verification is the gate, not the epilogue
The reliability gain comes from the verification step. The verification model acts as a critic: it checks a concrete rubric and either approves or returns actionable feedback.
def verify_node(self, state: SpecState) -> SpecState:
"""Quality verification using orchestrator model."""
response = self.verify_model.invoke([
SystemMessage(content="Review this draft. If acceptable, output APPROVED. If issues, output REVISE: <feedback>"),
HumanMessage(content=f"Task: {state['task']}\n\nDraft:\n{state['draft']}")
])
if "APPROVED" in str(response.content):
return {"verified": state['draft'], "needs_revision": False}
return {"needs_revision": True, "verified": str(response.content)}This is the difference between “pretty output” and “a system you can lean on at 6am.”
The verifier does not need to be an LLM every time. In good systems, verification is often cheaper and stricter than generation:
- JSON schema validation
- required citations
- contract checks
- diff review rules
- policy or RBAC checks
- bounded retries with a hard stop
The key is that approval has a shape. “Looks okay” is not a shape.
What I instrument now
If I expect an agent to do real work, I want enough telemetry to debug it like a service:
- state transitions
- revision count and revision reasons
- tool latency and failure rate
- artifact size and validation failures
- stop conditions and timeout reasons
This is also why I like bounded tools and visible task queues. When the artifact is bad, I want to know whether the problem was the model, the tool, the policy, or the workflow design.
Many “agent” products are really RAG pipelines with a nicer UI. That can still be useful. But it is a different thing. The practical distinction for me is simple:
- if the system can verify and revise against explicit criteria, it starts to behave like an agent,
- if it only retrieves context and generates once, it behaves like a generator with better inputs.
Concrete practices that helped:
- Start simple: small state + small tools beats a mega-prompt.
- Make the artifact inspectable: summaries, plans, PRs, tickets, and DAG steps are easier to debug than vibes.
- Test with real tasks: synthetic tasks hide the failure modes you care about.
- Be honest about models: smaller models are great for drafting and extraction; verification often needs a stricter model or a narrower rubric.
- Keep operator state visible: HUDs, task lists, traces, and workflow graphs are not polish. They are safety features.
Related examples:
Related Articles
Comments
Join the discussion. Be respectful.